An interactive and illustrated explanation of Hierarchical Reasoning Models
Making Gmail’s smart compose system sounds trivial until you’re tasked with running inference for 1.5 billion users with 90th percentile latency under 60ms and personalization based on user’s writing style!Here’s a breakdown of how google approached this:
Based on https://arxiv.org/pdf/1906.00080.
Challenges:
- extremely low latency: inference on almost every keystroke
- personalization at large scale (1.5B users)
- privacy: model should never expose personal information
- high quality suggestions in subtly different contexts
First up, preparing the data.
They supplement e-mail contents with extra context:
- Date and time: helps suggest good morning/evening, happy new year etc at the appropriate time
- Locale of the user: helps the model distinguish between en-US and en-GB spellings

They replace infrequent words and entities like personal names, URLs, e-mail addresses, phone numbers, etc. by special tokens so that the model is not exposed to them.
Then, they perform word level tokenization. The vocabulary contains the most frequent 50k English words.
Second, the model:
They experimented with LSTM and transformer models, and two different methods of feeding the inputs.
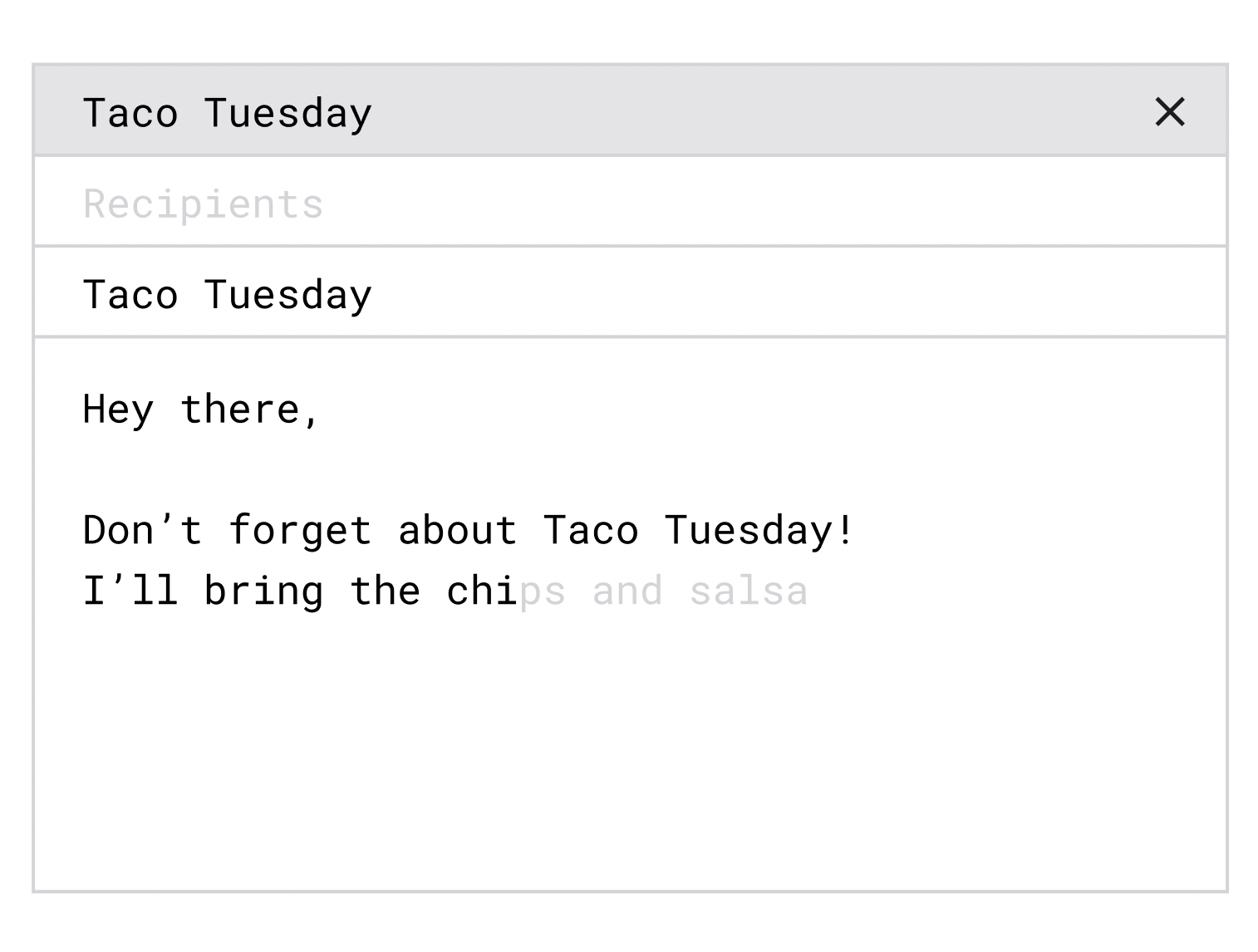
Method A: The input sequence is the current e-mail body. The extra context is separately encoded into one embedding and combined with the input sequence.
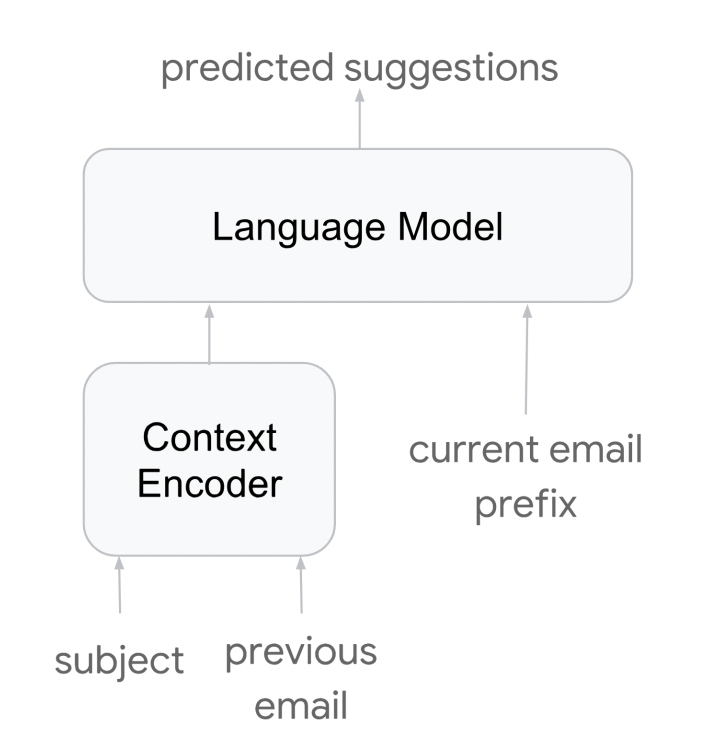
Method B: You combine all contextual information along with the prefix text in one long input sequence. This is simpler but the sequence length is longer.
They applied beam search during inference and evaluated the models with two metrics: Log Perplexity and ExactMatch@N.
ExactMatch for a predicted phrase that is N words long, the percentage of predicted phrase that exactly matches the first N words in the ground truth text.
Looking to balance inference quality and latency, they went ahead with method A of feeding inputs (faster due to smaller sequence lengths) and LSTMs (lower latency at slightly lower quality).
Now, let's talk about personalization:
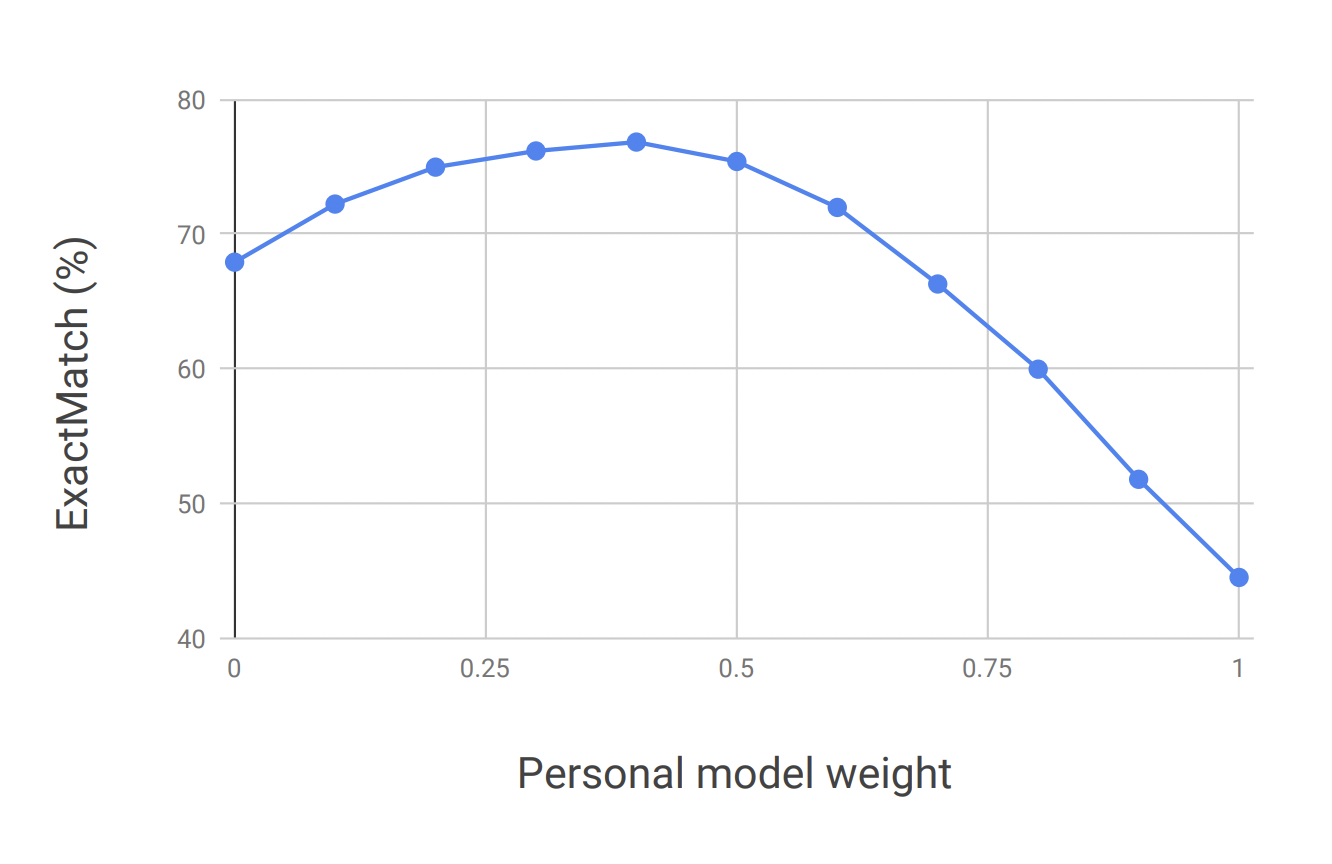
Users can have different writing styles and there are billions of them so they chose a lightweight n-gram language model which is easier to train and requires less data. It's also efficiently stored in a compact weighted finite automata.
While performing beam search, they interpolate between the probability values given by the two models.
Adding personalization improved ExactMatch scores as well as suggestion acceptance rates from the users.
An interesting idea they mention for future work is extending VAEs to language modelling. It could potentially making the smart compose suggestions more appropriate and diverse!